Shuffling is a fundamental operator for transferring data between stages (and nodes) in Apache Spark. It was already a cornerstone of the MapReduce paper in 2004, and has since stood the test of time as a generic data exchange primitive for dataflow engines, providing the basis for inter-node transfer of intermediary results. In scale-out SQL engines in particular, shuffles are the central operator to implement many key operators such as joins, aggregates, etc. Unfortunately, the original Spark paper lacks comprehensive documentation regarding the crucial implementation details of shuffle, and I could not find blog posts that go into the details, making it challenging to access precise and technical insights. This is a short article explaining the implementation of Spark Shuffle, followed by a discussion of its strengths and weaknesses.
Conceptually, the Shuffle is an all-to-all operator that consists in sending over the network all the outputs of the Map stage that are partitioned by key A to the Reducer nodes, so that the data becomes partitioned by a key B (the reduction key).
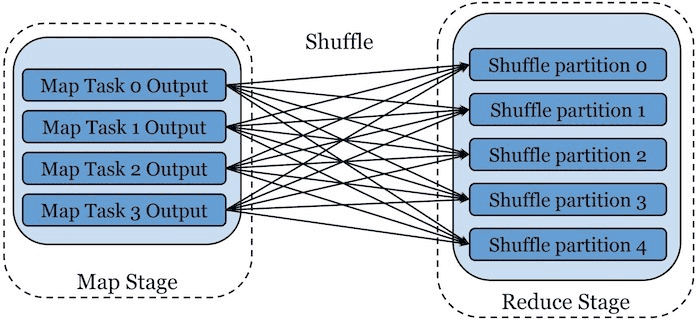
In Spark, mappers partition their own data, and generate a Map Output File spilled to disk (always), and partitioned per reducer. Each executor runs a Shuffle Service in the background that makes such Map Output Files available to consumers through TCP. Map tasks sort all the transformed records according to the hashed partition keys. During this process, the map task might spill the intermediate data to disk if it cannot sort the entire data in memory. Once sorted, the shuffle block is generated, where all records belonging to the same shuffle partition are grouped together into a shuffle block, along with a shuffle index file that tracks the block boundary offset for efficient retrieval.

Every Reducer will then read all partitions that are assigned to them from the Shuffle Service of every Mapper, and then will perform a sort by key before consuming the input partition(s). Just as on the producer-side, the sort by key may spill to disk if available memory is not sufficient to sort all input Map Output Files. The Shuffle Service will use the index files to lookup the requested blocks. In general, shuffles on scale-out DBMS are a notoriously slow operation. In fact, shuffles are one of the main factors limiting scalability of distributed analytics engines, as adding more nodes to a slow cluster provokes more data to be shuffled, hence causing the speedup to plateau. To make matters worse, Shuffle IO grows quadratically with the data, as reducers have to read from every mapper.
The good
A major strength of Spark’s shuffling implementation is that it is handled by a service independent from the executor process. Not only does it make fault tolerance easier and more scalable, because failures don’t trigger full tasks recompute, it also loosely decouples the producers from the consumers (loosely because the reducers still need to wait for the all producers to finish spilling the shuffle files). This enables fetching blocks even when the Spark executor is down, whether for garbage collection or else, allowing to free up idle executors as well.
The second, associated key strength of the strategy is that map output files are systematically spilled to disk. This is not only important to facilitate the decoupling of the shuffle service from the executors, it ultimately is a tradeoff that favors scalability, because shuffling in-memory will often result in Out of Memory errors on more challenging jobs, as seen in some MPP engines like Presto, for example.
The bad
The weaknesses of the implementation have been thoroughly researched, as shuffling is an obvious bottleneck in scaling Spark jobs, and we can classify them in two categories. Technical weaknesses that can be improved with better awareness of I/O notably, and conceptual weaknesses that put in the question the design of the shuffle service.
On the hardware-software codesign side, one of the limitation of Spark's implementation is suboptimal disk (HDD) access patterns. The authors of Riffle identify 3 key hardware metrics that should be optimized for better disk performance: disk seek time, number of small IOs and write amplifications (number of write operations). Disk seek time depends on access pattern (random vs. sequential), the number of small IOs depends on the size of requests IO blocks (it is better to read one large file than many small files), and write amplifications depends on the number of times spill-to-disk occurs. Apart from pure IO performance, because shuffle data needs to spill to disk, the shuffle operator may cause memory or disk resources exhaustion, causing expensive task retries or even job failures. Finally, under heavy loads, the authors of Magnet observe that the shuffle service may become temporarily unavailable, causing unnecessary retries.
The Riffle paper mostly tackles I/O patterns, and proposes to merge Map Output Files from multiple mappers to reduce the number of file IOs and allow the Reducers to read sequentially. However, naively merging MOFs may result in increased write amplification (N-way merge creates N more writes), so they add that mappers should share a write-ahead buffer for each reduce partition. Some of the other limitations may be addressed by over-provisioning storage, but the negative implications are obvious. The Magnet paper instead proposes that mappers directly push shuffle data to the reducers in a best effort attempt.
On the conceptual side however, another key limitation of Spark's Shuffle implementation is that the operator acts as a barrier between subsequent stages, because Reducers have to wait for all Mappers to write their Map Output File before starting to read. Unlike MapReduce-style shuffles, where the first row in the repartitioned data set can be used after all rows have been sent and sorted, in BigQuery, Google’s cloud data warehouse as a service, each shuffled row can be consumed by BigQuery workers as soon as it's created by the producers. This makes it possible to execute distributed operations in a pipeline. A fully disaggregated shuffle service, implies that a separate set of nodes is tasked with storing Map Output Files. Such implementations then differ by how they reduce latency. BigQuery's Shuffle Service is an in-memory remote service. Implementations leveraging RDMA have also been proposed.